






Đăng ký nhận bản tin của chúng tôi và luôn là người đầu tiên nghe về những gì đang xảy ra.
Thiết kế hệ thống dỡ pallet bằng robot điều khiển bằng thị giác 3D cho vật liệu nhiều khổ
Feb 13, 2023Thiết kế hệ thống dỡ pallet bằng robot điều khiển bằng thị giác 3D cho vật liệu nhiều khổ
Robot loại bỏ vật liệu Cánh tay robot Bộ điều khiển robot
Tóm tắt: Trong sản xuất công nghiệp và logistics, việc dỡ hàng khỏi pallet bằng robot là một trong những ứng dụng phổ biến. Tháo dỡ vật liệu là tình huống trong đó hàng hóa có kích thước khác nhau (tức là hàng hóa có kích thước, trọng lượng hoặc kết cấu khác nhau) được chất lên pallet để giao hàng. Việc dỡ hàng bằng robot trước đó chỉ áp dụng cho việc dỡ hàng đơn lẻ và yêu cầu hàng hóa phải được sắp xếp theo một thứ tự cố định và robot không có khả năng nhận thức; Hệ thống dỡ pallet được điều khiển bằng robot được mô tả trong bài viết này được trang bị khả năng nhận biết môi trường theo thời gian thực để hướng dẫn hành động gắp, từ đó giải quyết các vấn đề về kích thước thay đổi của các vật thể cần được dỡ xuống và việc bố trí không đều các hệ thống dỡ pallet vật liệu nhiều thước đo.
Từ khóa: Nhận dạng tầm nhìn 3D, robot, xếp pallet lai, định vị đối tượng, thuật toán dỡ pallet
Trong sản xuất công nghiệp và hậu cần, nhiều loại robot công nghiệp khác nhau có thể được sử dụng để tối ưu hóa dòng hàng hóa và một trong những ứng dụng phổ biến là dỡ bỏ vật liệu. "Việc dỡ hàng bằng robot" thường đề cập đến quá trình dỡ hàng tuần tự khỏi pallet bằng cách sử dụng cánh tay robot và có thể được sử dụng để thay thế lao động thủ công đơn giản nhưng nặng nhọc. Trong lĩnh vực hậu cần, có những tình huống trong đó hàng hóa có kích thước khác nhau (tức là, kích cỡ, trọng lượng hoặc kết cấu khác nhau) được giao trong hộp, như trong Hình 1.
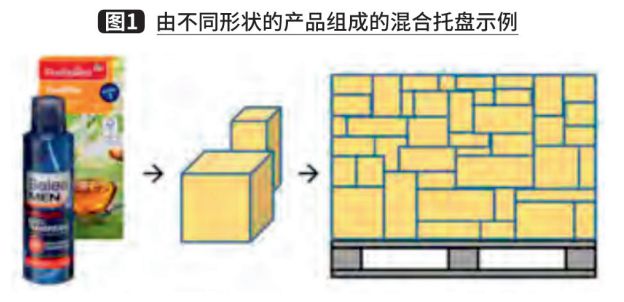
Tuy nhiên, các hệ thống dỡ hàng bằng robot ban đầu chủ yếu được điều khiển thủ công để hoàn thành việc kẹp robot, chỉ áp dụng cho việc dỡ một hàng hóa duy nhất và yêu cầu hàng hóa phải được sắp xếp theo một trật tự cố định và robot không có khả năng nhận thức để phản ứng với những thay đổi bên ngoài. Tuy nhiên, hệ thống dỡ vật liệu nhiều khổ yêu cầu robot phải có nhận thức về môi trường theo thời gian thực để hướng dẫn hành động kẹp vì các vật thể được dỡ có kích thước khác nhau và được đặt không đều.
Với sự phát triển của nhiều loại cảm biến quang học, công nghệ thị giác máy tính đã dần được đưa vào các nhiệm vụ nắm bắt của robot nhằm cải thiện khả năng thu thập thông tin bên ngoài của robot. Hệ thống dỡ hàng bằng robot điều khiển bằng thị giác thường chứa năm mô-đun, đó là mô-đun thu thập thông tin tầm nhìn, mô-đun phân tích và định vị đối tượng, mô-đun tính toán vị trí nắm bắt, mô-đun chuyển đổi tọa độ tay-mắt và mô-đun lập kế hoạch chuyển động, như trong Hình 2. Trong số đó , ba mô-đun đầu tiên là phần chính của hệ thống thị giác, chịu trách nhiệm thu thập và xử lý thông tin hình ảnh cũng như cung cấp các tư thế đối tượng. Hai mô-đun cuối cùng chủ yếu được sử dụng để cung cấp thông tin điều khiển cho robot và hoàn thành chức năng nắm bắt. Sau đây, chúng tôi sẽ giới thiệu từng mô-đun, các phương pháp phổ biến và trường hợp triển khai.
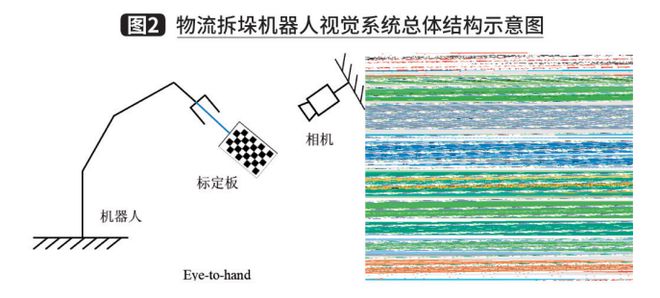
I. Mô-đun thu thập thông tin tầm nhìn
Vai trò của mô-đun thu thập thông tin thị giác là thu thập thông tin hình ảnh và cung cấp đầu vào cho các bước tiếp theo. Hiện tại, các đầu vào hình ảnh thường được sử dụng bao gồm hình ảnh 2D RGB, hình ảnh đám mây điểm 3D và hình ảnh 2D và 3D RGB-D kết hợp. Trong số đó, việc nắm bắt cánh tay robot được hỗ trợ bằng thị giác dựa trên hình ảnh 2D RGB hiện là một giải pháp hoàn thiện trong công nghiệp, giúp biến vấn đề nắm bắt của robot thành vấn đề phát hiện mục tiêu đối tượng hoặc phân đoạn hình ảnh trên hình ảnh RGB. Tuy nhiên, tầm nhìn 2D thiếu thông tin tỷ lệ tuyệt đối của vật thể và chỉ có thể được sử dụng trong các điều kiện cụ thể, chẳng hạn như các tình huống có pallet cố định và kích thước vật liệu đã biết. Đối với các tình huống không xác định được thước đo vật liệu, mô-đun tầm nhìn được yêu cầu cung cấp cho robot thông tin kích thước tuyệt đối chính xác của vật thể cần nắm bắt, do đó, chỉ có thể hình ảnh đám mây điểm 3D hoặc hình ảnh RGB-D với sự kết hợp giữa 2D và 3D. đã sử dụng. So với thông tin RGB, thông tin RGB-D chứa thông tin khoảng cách không gian từ máy ảnh đến đối tượng; so với hình ảnh đám mây điểm 3D, thông tin RGB-D chứa thông tin kết cấu màu sắc phong phú. Do đó, hình ảnh RGB-D có thể được sử dụng làm thông tin trực quan đầu vào của hệ thống dỡ vật liệu nhiều thước đo.
Mô-đun phân tích và định vị đối tượng
Mô-đun phân tích và định vị đối tượng nhận dữ liệu đầu vào từ mô-đun thu thập thông tin thị giác, phân tích các vật liệu có trong cảnh và lấy thông tin chính như vị trí và tư thế của chúng, sau đó nhập thông tin quan trọng này vào mô-đun tính toán tư thế nắm bắt. Nói chung, vấn đề định vị vật liệu trong hệ thống dỡ hàng bằng robot có thể được chuyển thành vấn đề phát hiện mục tiêu hoặc phân đoạn hình ảnh trong trường thị giác. Giải pháp nắm bắt robot dựa trên tầm nhìn RGB-D trước tiên có thể thực hiện phát hiện mục tiêu 2D hoặc phân đoạn hình ảnh 2D trên hình ảnh RGB cho vật liệu, sau đó hợp nhất bản đồ độ sâu để xuất ra kích thước tuyệt đối của đối tượng và tư thế nắm bắt; hoặctrực tiếp thực hiện phát hiện hoặc phân đoạn mục tiêu trên bản đồ đám mây điểm 3D. Sau đây sẽ là phần giới thiệu ngắn gọn về công việc liên quan.
Phát hiện mục tiêu 1.2D
Đầu vào của phát hiện mục tiêu 2D là hình ảnh RGB của cảnh và đầu ra là lớp và vị trí của đối tượng trong ảnh và vị trí được đưa ra ở dạng đường viền hoặc trung tâm. Các phương pháp phát hiện mục tiêu có thể được chia thành các phương pháp truyền thống và phương pháp dựa trên học sâu. Các phương pháp phát hiện mục tiêu truyền thống thường sử dụng một cửa sổ trượt để duyệt toàn bộ hình ảnh, với mỗi cửa sổ trở thành một vùng ứng cử viên. Đối với mỗi vùng ứng cử viên, các đặc điểm trước tiên được trích xuất bằng SIFT, HOG và các phương pháp khác, sau đó bộ phân loại được huấn luyện để phân loại các đặc điểm được trích xuất. Ví dụ: thuật toán DPM cổ điển sử dụng SVM để phân loại các tính năng HOG đã được sửa đổi nhằm đạt được hiệu quả phát hiện mục tiêu. Phương pháp truyền thống có hai nhược điểm rõ ràng: thứ nhất, rất tốn thời gian để duyệt toàn bộ hình ảnh bằng cửa sổ trượt, khiến độ phức tạp về thời gian của thuật toán cao và khó áp dụng cho các kịch bản quy mô lớn hoặc thời gian thực; thứ hai, các tính năng được sử dụng thường cần phải được thiết kế thủ công, khiến các thuật toán như vậy phụ thuộc nhiều hơn vào trải nghiệm và kém mạnh mẽ hơn.
2. Phân đoạn hình ảnh hai chiều
Phân đoạn hình ảnh có thể được coi là nhiệm vụ phân loại hình ảnh ở cấp độ pixel. Tùy thuộc vào ý nghĩa của kết quả phân đoạn, phân đoạn hình ảnh có thể được chia thành phân đoạn theo ngữ nghĩa và phân đoạn thực thể. Phân đoạn ngữ nghĩa phân loại từng pixel trong hình ảnh thành một danh mục tương ứng, trong khi phân đoạn phiên bản không chỉ thực hiện phân loại cấp pixel mà còn phân biệt các phiên bản khác nhau trên cơ sở các danh mục cụ thể. Liên quan đến hộp giới hạn phát hiện mục tiêu, phân đoạn cá thể có thể chính xác đến các cạnh của đối tượng; Liên quan đến phân đoạn ngữ nghĩa, phân đoạn cá thể cần gắn nhãn cho các cá thể khác nhau của các đối tượng tương tự trên biểu đồ. Trong các ứng dụng dỡ pallet, chúng ta cần trích xuất chính xác các cạnh của vật liệu để tính toán vị trí kẹp, vì vậy chúng ta cần sử dụng các kỹ thuật phân đoạn phiên bản. Các kỹ thuật phân đoạn hình ảnh hiện có có thể được chia thành các phương pháp truyền thống và phương pháp dựa trên học sâu.
Hầu hết các phương pháp phân đoạn ảnh truyền thống đều dựa trên sự giống nhau hoặc đột biến của các giá trị màu xám trong ảnh để xác định xem các pixel có thuộc cùng một lớp hay không. Các phương pháp thường được sử dụng bao gồm phương pháp dựa trên lý thuyết đồ thị, phương pháp dựa trên phân cụm và phương pháp dựa trên phát hiện cạnh.
Các phương pháp dựa trên deep learning đã cải thiện đáng kể độ chính xác của phân đoạn hình ảnh 2D so với các phương pháp truyền thống. Các khung mạng thần kinh sâu điển hình, chẳng hạn như AlexNet, VGGNet, GoogleNet, v.v., thêm một lớp được kết nối đầy đủ ở cuối mạng để tích hợp tính năng, theo sau là softmax để xác định danh mục của toàn bộ hình ảnh. Để giải quyết bài toán phân đoạn ảnh, khung FCN thay thế các lớp được kết nối đầy đủ này bằng các lớp giải mã, biến đầu ra của mạng từ xác suất một chiều thành ma trận có cùng độ phân giải với đầu vào, đây là công trình tiên phong áp dụng học sâu đến phân đoạn ngữ nghĩa.
3. Phát hiện mục tiêu 3D
Tính năng phát hiện mục tiêu 3D cho phép robot dự đoán và lập kế hoạch chính xác về hành vi cũng như đường đi của chúng bằng cách tính toán trực tiếp vị trí 3D của vật thể để tránh va chạm và vi phạm. Phát hiện mục tiêu 3D được chia thành camera một mắt, camera hai mắt, camera đa mắt, quét LIDAR bề mặt đường, camera độ sâu và camera hồng ngoại phát hiện mục tiêu theo loại cảm biến. Nhìn chung, hệ thống âm thanh nổi/đa tầm nhìn bao gồm camera đa tầm nhìn hoặc LiDAR cho phép đo đám mây điểm 3D chính xác hơn, trong đó các phương pháp dựa trên nhiều chế độ xem có thể sử dụng thị sai từ hình ảnh của các chế độ xem khác nhau để thu được bản đồ độ sâu; các phương pháp dựa trên đám mây điểm lấy thông tin mục tiêu từ các đám mây điểm. Để so sánh, do dữ liệu độ sâu của các điểm có thể được đo trực tiếp nên việc phát hiện mục tiêu 3D dựa trên đám mây điểm về cơ bản là vấn đề phân định điểm 3D và do đó trực quan và chính xác hơn.
Thứ ba, mô-đun tính toán tư thế chụp
Mô-đun tính toán tư thế cầm nắm sử dụng thông tin tư thế vị trí của đối tượng mục tiêu xuất ra từ mô-đun thứ hai để tính toán tư thế cầm nắm của robot. Vì thường có nhiều mục tiêu có thể nắm bắt được trong hệ thống dỡ vật liệu có nhiều thước đo, mô-đun này sẽ giải quyết hai vấn đề "nắm mục tiêu nào" và "nắm bắt như thế nào".
Bước đầu tiên là giải quyết vấn đề "cái nào". Mục tiêu của vấn đề này là chọn mục tiêu thu thập thông tin tốt nhất trong số nhiều mục tiêu thu thập thông tin và mục tiêu "tốt nhất" ở đây thường cần được xác định theo yêu cầu thực tế. Cụ thể, chúng ta có thể định lượng một số chỉ số có tác động đến phán đoán thu thập thông tin theo tình hình thực tế, sau đó ưu tiên các chỉ số này.
Bước thứ hai là giải quyết vấn đề “làm thế nào đểbắt". Chúng ta có thể chọn phân tích và tính toán tư thế nắm bắt bằng phân tích cơ học, hoặc trước tiên chúng ta có thể phân loại đối tượng theo phương pháp học, sau đó chọn điểm nắm bắt theo phân loại, hoặc trực tiếp hồi quy tư thế nắm bắt.
Thứ tư, mô-đun chuyển đổi tọa độ tay-mắt
Với mô-đun thứ ba, chúng ta đã có được tư thế cầm nắm khả thi. Tuy nhiên, tư thế nắm chặt dựa trên tư thế trong hệ tọa độ máy ảnh và tư thế nắm chặt cần phải được chuyển đổi sang hệ tọa độ robot trước khi có thể thực hiện lập kế hoạch chuyển động. Trong các hệ thống dỡ pallet, hiệu chuẩn bằng tay thường được sử dụng để giải quyết vấn đề này. Tùy thuộc vào vị trí cố định của máy ảnh, phương pháp hiệu chỉnh tay-mắt có thể được chia thành hai trường hợp. Một là camera được cố định trên cánh tay robot và camera di chuyển cùng với cánh tay, gọi là Eye-in-hand, như trên Hình 3. Trong mối quan hệ này, mối quan hệ vị trí giữa đế robot và tấm hiệu chuẩn không đổi trong hai chuyển động của cánh tay robot và đại lượng được giải quyết là mối quan hệ vị trí giữa camera và hệ tọa độ đầu robot. Loại camera còn lại được cố định trên một giá đỡ riêng, gọi là Eye-to-hand, như trong Hình 4. Trong trường hợp này, mối quan hệ về thái độ giữa phần cuối của robot và tấm hiệu chuẩn vẫn giữ nguyên trong hai chuyển động của robot. cánh tay và giải pháp là mối quan hệ thái độ giữa camera và hệ tọa độ của đế robot. Cả hai trường hợp cuối cùng đều được chuyển thành bài toán nghiệm với AX=XB và phương trình có thể được chuyển thành phương trình tuyến tính bằng cách sử dụng đại số nhóm Lie và đại số Lie để giải các đại lượng quay và tịnh tiến tương ứng.
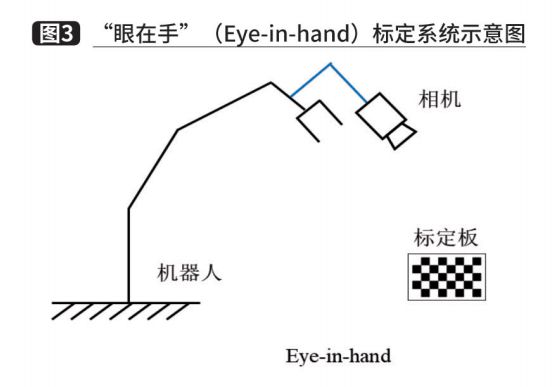
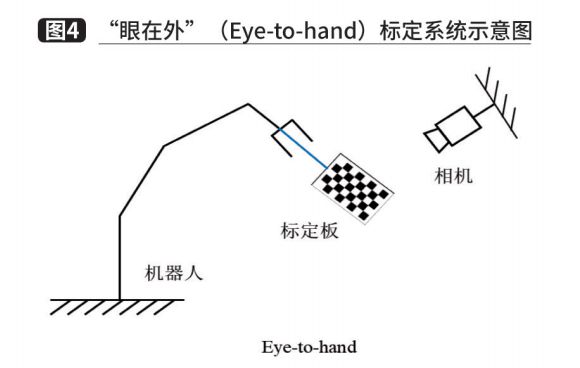
Thứ năm. Mô-đun lập kế hoạch chuyển động
Mô-đun này chủ yếu xem xét động học, động lực học, phân tích cơ học và lập kế hoạch chuyển động của robot để lập kế hoạch đường chuyển động khả thi không va chạm với môi trường. Bằng cách nhân tư thế nắm trong hệ tọa độ camera thu được từ mô-đun tính toán tư thế nắm với ma trận chuyển đổi được hiệu chỉnh bởi mô-đun chuyển đổi tọa độ tay-mắt, chúng ta có thể thu được tư thế nắm trong hệ tọa độ cánh tay robot. Dựa trên tư thế này, việc lập kế hoạch chuyển động có thể được thực hiện và cánh tay robot có thể được hướng dẫn để hoàn thành nhiệm vụ dỡ hàng. Do đó, đầu vào của mô-đun lập kế hoạch chuyển động là vị trí bắt đầu và mục tiêu của cánh tay robot, còn đầu ra là đường chuyển động của cánh tay robot.
Thuật toán lập kế hoạch chuyển động hoàn chỉnh có thể được chia thành ba bước sau.
Bước 1: Giải động học nghịch đảo. Để tránh các vấn đề như điểm kỳ dị, việc lập kế hoạch chuyển động của cánh tay robot thường được thực hiện trong không gian khớp. Vì vậy, trước tiên chúng ta nên thực hiện giải động học nghịch đảo dựa trên các tư thế đầu vào để thu được các giá trị khớp tương ứng với các tư thế.
Bước 2: Lập kế hoạch đường đi. Với thuật toán quy hoạch đường đi, chúng ta có thể có được đường chuyển động của cánh tay robot. Mục tiêu của bước này gồm hai phần: một là tránh chướng ngại vật, để đảm bảo rằng cánh tay robot không va chạm với các vật thể khác trong cảnh trong quá trình di chuyển; thứ hai là cải thiện tốc độ hoạt động nhằm tăng hiệu quả hoạt động của hệ thống. Bằng cách lập kế hoạch cho đường chuyển động hợp lý, thời gian hoạt động của một lần nắm cánh tay robot có thể được rút ngắn hơn, nhờ đó nâng cao hiệu quả.
Bước 3: Nội suy thời gian. Tuy nhiên, mặc dù chúng ta đã có thể có được một đường chuyển động khả thi thông qua việc quy hoạch đường đi, nhưng đường dẫn này bao gồm hết điểm vị trí này đến điểm vị trí khác. Khi cánh tay robot chạy dọc theo đường này, nó cần giữ nguyên tốc độ tăng và giảm tốc nên sẽ ảnh hưởng đến tốc độ chạy. Vì lý do này, chúng ta cần thực hiện phép nội suy theo thời gian để thu được thông tin về vận tốc, gia tốc và thời gian cho từng điểm trên đường đi khi cánh tay robot di chuyển đến điểm đó. Bằng cách này, cánh tay robot có thể chạy liên tục và trơn tru, nhờ đó nâng cao hiệu quả.
Thứ sáu. Ví dụ triển khai
Dựa trên nghiên cứu trên, có thể sử dụng hệ thống thị giác hoàn chỉnh bao gồm camera độ sâu 3D, hệ thống chiếu sáng, máy tính và phần mềm xử lý thị giác trong kịch bản nhận dạng vật liệu hộp mảnh để thu được một số thông tin đặc biệt về vật thể thực và thông tin thu được thông qua điều này. Hệ thống có thể được sử dụng để hoàn thành một số nhiệm vụ đặc biệt, chẳng hạn như lấy vị trí hộp thông qua hệ thống thị giác, hệ thống này có thể hướng dẫn robot nắm bắt và lấy thông tin số lượng hộp làm hiệu chuẩn cho nhiệm vụ. Các thành phần chính của hệ thống này, như trong Hình 5.
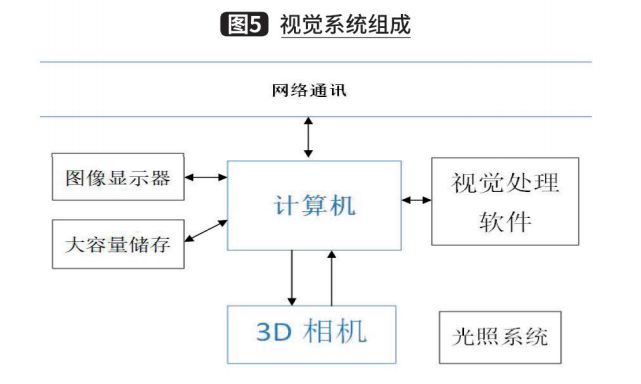
Camera 3D và hệ thống ánh sáng chủ yếu được sử dụng để chụp ảnh, trong đó camera 3D có thể thu được dữ liệu độ sâu trong một phạm vi nhất định. Và hình ảnh kỹ thuật số có liên quan đến hệ thống chiếu sáng. Mặt khác, máy tính bao gồm các thiết bị tính toán và lưu trữ đa năng để lưu hình ảnh, xử lý hình ảnh thông qua phần mềm thị giác chuyên dụng và cả cho mạng.giao tiếp với các hệ thống khác. Màn hình hiển thị hình ảnh tạo điều kiện cho người vận hành vận hành phần mềm xử lý hình ảnh và giám sát hoạt động của hệ thống. Bộ nhớ dung lượng lớn được sử dụng để lưu trữ vĩnh viễn hoặc tạm thời hình ảnh hoặc dữ liệu khác. Mặt khác, phần mềm thị giác chuyên dụng bao gồm xử lý hình ảnh kỹ thuật số, phân tích dữ liệu hình ảnh và một số chức năng đặc biệt.
Nói chung, camera độ sâu 3D có tốc độ khung hình từ 1 đến 30 khung hình / giây, độ phân giải hình ảnh RGB là 640×480, 1280×960, đặc biệt 1920×1080, 2592×1944 và phạm vi độ sâu khoảng 500mm đến khoảng 5000mm.
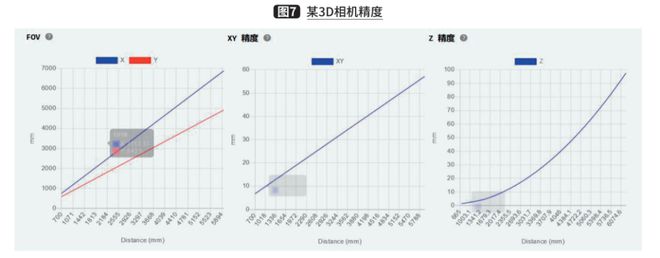
Và tùy theo mức giá mà có độ chính xác và phạm vi khác nhau. Dưới đây là ví dụ về một thương hiệu camera 3D có thông số như hình 6 và độ chính xác như hình 7.

Với máy ảnh 3D, bạn có thể thu được hình ảnh RGB và hình ảnh chiều sâu của các cảnh đặc biệt và theo quá trình xử lý và phân tích những hình ảnh này (xem Hình 8), bạn có thể nhận được một số thông tin về vị trí, số lượng và thông tin của các vật thể trong bối cảnh.

Hộp hình chữ nhật trong Hình 9 là sơ đồ vị trí lấy hộp được xác định sau khi xử lý. Thứ tự phía trên bên trái, phía dưới bên trái, phía trên bên phải và phía dưới bên phải lần lượt là “2, 3, 3, 2”, tức là tay robot sẽ cầm hai hộp bên trái, ba hộp bên trái, ba hộp bên phải. bên phải và hai ô bên phải theo thông tin vị trí do hệ thống nhận dạng hình ảnh đưa ra.

Thứ bảy. Bản tóm tắt
Trong bài báo này, chúng tôi đã giới thiệu khung và các phương pháp phổ biến của hệ thống xếp dỡ robot vật liệu đa thước đo hướng dẫn bằng thị giác 3D, đồng thời xác định một số mô-đun cơ bản mà khung cần phải có, cụ thể là mô-đun thu thập thông tin tầm nhìn, mô-đun phân tích và định vị đối tượng, mô-đun tính toán vị trí nắm bắt, mô-đun chuyển đổi tọa độ tay-mắt và mô-đun lập kế hoạch chuyển động, đồng thời giải thích các nhiệm vụ chính và phương pháp chung của từng mô-đun. Trong các ứng dụng thực tế, các phương pháp khác nhau có thể được sử dụng để triển khai các mô-đun này khi cần mà không ảnh hưởng đến chức năng của các mô-đun khác và toàn bộ hệ thống.
Đăng ký nhận bản tin của chúng tôi và luôn là người đầu tiên nghe về những gì đang xảy ra.
ĐT : 0086 189 5658 0164
E-mail : [email protected]
Whatsapp : 0086 189 5658 0164
39# JinRong Rd,ShuangFeng Econimic Development Zone,Hefei city,Anhui Province,China

© 2026 Công ty TNHH Công nghệ quang điện tử Hợp Phì Mingde Đã đăng ký Bản quyền
 IPv6 MẠNG ĐƯỢC HỖ TRỢ
IPv6 MẠNG ĐƯỢC HỖ TRỢ